Building Data Product#
Overview#
The Building Data Product phase transforms your approved requirements into a fully functional data product through systematic development, testing, and deployment. This phase focuses on implementing robust data pipelines, establishing observability, and ensuring your data product meets all technical and business requirements.
What you will learn#
After completing this chapter, you will understand how to:
- Implement secure data access patterns and connectivity to source systems
- Build scalable data pipelines using modern ETL/ELT frameworks
- Establish comprehensive observability and monitoring for your data products
- Implement data quality controls and automated testing
- Create proper documentation and data lineage tracking
- Set up output ports for downstream consumption
- Follow CI/CD best practices for data product deployment
Key Personas & Stakeholders - RACI Matrix#
| Activity | Data Product Manager | Data Engineer | Solution Architect | DevOps Engineer | Data Analyst | Business Stakeholder |
|---|---|---|---|---|---|---|
| Pipeline Implementation | A | R | C | C | I | I |
| Data Quality Setup | C | R | C | I | A | C |
| Observability Implementation | C | R | A | R | I | I |
| Documentation Creation | A | R | C | I | C | C |
| Output Port Configuration | C | R | A | C | C | I |
| CI/CD Pipeline Setup | C | R | C | A | I | I |
| Testing & Validation | A | R | C | C | R | C |
R = Responsible, A = Accountable, C = Consulted, I = Informed
Prerequisites#
- Requirements: Requirements Specification approved by Product Owner and core stakeholders
- Team Setup: Delivery team is defined, allocated, and has completed onboarding
- Project Foundation: A Working Project and Code Repository created
- Technical Access: All team members have Technical Prerequisites including:
- Databricks workspace access and configuration
- Required cloud platform permissions
- Development tools and IDE setup
- Architecture: High-level architecture from feasibility assessment finalized
Step-by-Step Process#
Step 1: Secure Data Source Access#
Objective: Establish secure, reliable connections to all required data sources and validate data availability.
-
Identify and Access Data Sources:
Here are some common data sources you may need to connect to:
- Database systems: SQL Server, PostgreSQL, Oracle, MySQL
- Cloud storage: Azure Blob Storage, AWS S3, Google Cloud Storage
- APIs and web services: REST APIs, GraphQL endpoints, SOAP services
- File shares and data lakes: Network file systems, HDFS, Delta Lake
- Message queues: Kafka, Azure Service Bus, AWS SQS
-
Configure Authentication and Authorization:
- Set up service accounts with principle of least privilege
- Configure OAuth 2.0, API keys, or certificate-based authentication
- Avoid using Personal Access Tokens (PATs), use service principals or managed identities
-
Test Connectivity and Data Availability:
- Test authentication mechanisms in target environments
- Validate data schema and sample data
- Confirm data refresh schedules and availability windows
- Implement error handling for connection failures
-
Document Access Patterns and Requirements:
Define and document the following:
- Connection strings and authentication methods
- Data refresh schedules and availability windows
- Rate limits and usage quotas
- Error handling and retry policies
- Performance benchmarks and SLA requirements
The above should be part of your technical design specifications. You can document these in:
- Manual setup: Create
design_specifications.mdunder thedocumentation/folder in your repository - Template-based setup: Use dc-template-core which provides structured documentation templates and placeholders for design specifications
- Deployment documentation: Follow dc-release documentation guide for environment-specific configuration and deployment specifications
Security Best Practice
Use Databricks secrets or similar secret management services to store connection credentials. Never hardcode sensitive information in your code.
Example
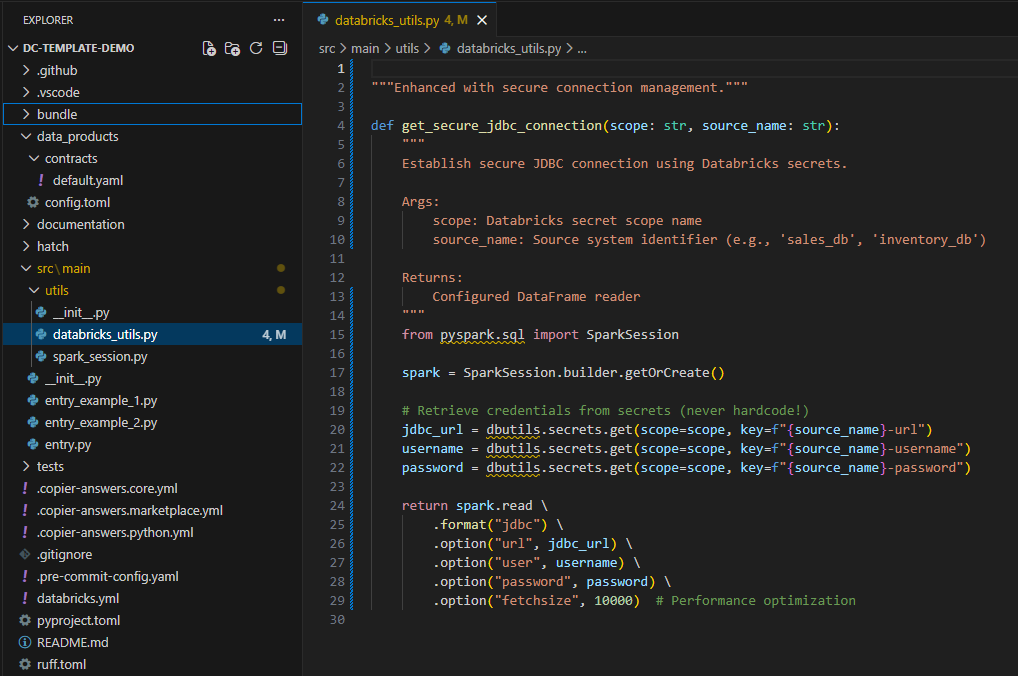
Tip
The dc-template-python-project provides a quick start template with a deployable python project setup where you can easily build these type of transformations for your use case.
Expected Outcome: Verified access to all data sources with documented connection patterns
Step 2: Implement Data Pipeline Architecture#
Objective: Build robust, scalable data pipelines following established patterns.
Source to Landing Zone Implementation#
The landing zone serves as a buffer layer that ingests raw data from source systems without transformation. This stage is essential when you need to decouple data ingestion from processing, handle varying data arrival patterns, or maintain an immutable copy of source data for audit and reprocessing purposes.
When to implement Source to Landing:
- When source systems have limited availability windows
- When you need to process large volumes requiring different processing schedules
- When regulatory requirements mandate raw data preservation
- When multiple downstream consumers need access to the same source data
-
Set up raw data ingestion pipelines: - Configure scheduled data extraction jobs - Implement streaming ingestion for real-time sources - Set up file monitoring for batch file arrivals - Handle different data formats (JSON, CSV, Parquet, Avro)
-
Implement change data capture (CDC) where applicable: - Configure CDC for transactional systems - Set up incremental extraction based on timestamps - Implement watermarking for streaming data - Handle deletes and updates appropriately
-
Add data validation at ingestion point: - Verify file integrity and completeness - Validate basic schema compliance - Check for required fields and data types - Implement data quality alerts for critical failures
Example
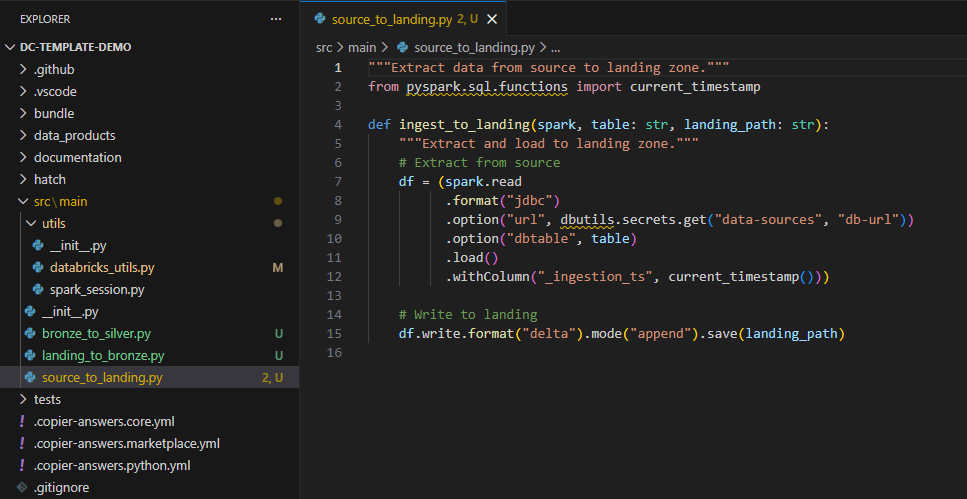
Landing to Bronze (Source-Aligned Data Products)#
The bronze layer serves as your source of truth for raw, validated data. Here's how to implement the transformation:
-
Apply data cleansing and standardization: - Remove or fix malformed records - Standardize date formats and data types - Handle null values and missing data - Apply consistent naming conventions
-
Implement data partitioning and bucketing strategies: - Partition by date/time for time-series data - Use appropriate partition sizes (avoid small files) - Implement bucketing for large datasets - Optimize for downstream query patterns
-
Implement load strategies: - Full refresh: Complete dataset replacement (for small, static datasets) - Incremental load: Process only new/changed records (for large, dynamic datasets) - Merge/Upsert: Handle updates and inserts (for transactional data) - Configure appropriate checkpointing and recovery mechanisms
-
Add audit columns for tracking: - Source system identifiers - Ingestion timestamps - Data lineage information - Processing batch/job identifiers
Example
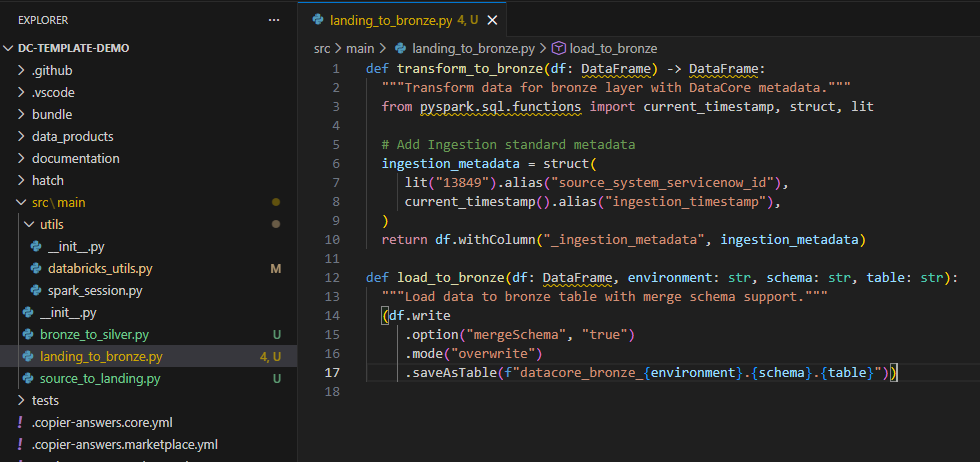
Tip
The dc-template-python-project provides a quick start template with a deployable python project setup where you can easily build these type of transformations for your use case.
Bronze to Silver/Gold Transformations#
The silver and gold layers apply business logic and create consumption-ready datasets. Silver typically contains cleaned, conformed data suitable for analytics, while gold provides aggregated, domain-specific datasets optimized for specific business use cases.
-
Create Physical Model if needed: Read here to know more
-
Apply business logic transformations: - Implement business rules and calculations - Create derived fields and computed columns - Apply data masking for sensitive information - Standardize business terminology and definitions
-
Implement aggregations and calculations: - Create pre-computed metrics and KPIs - Build rolling averages, cumulative sums, and trends - Implement time-based aggregations (daily, weekly, monthly) - Generate statistical summaries and data profiles
-
Join multiple data sources as required: - Combine related datasets using appropriate join types - Create comprehensive customer or product views
Example
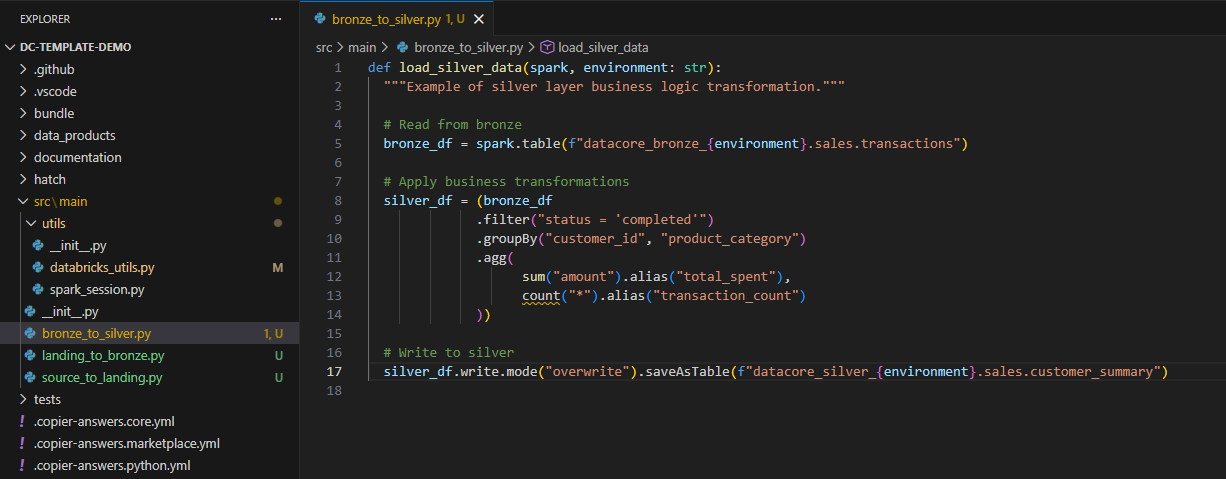
Tip
The dc-template-python-project provides a quick start template with a deployable python project setup where you can easily build these type of transformations for your use case.
Expected Outcome: Functional data pipelines processing data through all required layers
Step 3: Establish Comprehensive Observability#
Objective: Implement monitoring, alerting, and performance tracking for your data pipelines.
-
Define Key Metrics:
- Data Quality Metrics: Completeness, accuracy, consistency
- Performance Metrics: Processing time, throughput, resource utilization
- Business Metrics: Record counts, data freshness, SLA compliance
-
Implement Pipeline Monitoring:
- Schedule and monitor pipeline executions via Databricks Asset Bundles and Databricks Jobs. This can be setup using the dc-template-core and dc-template-python-project templates.
-
Set up Alerting Rules:
- Configure webhook notifications via Databricks Asset Bundles using dc-template-core and dc-template-python-project templates.
- Data quality threshold violations
- Performance degradation alerts
- Data freshness SLA breaches
-
Create Monitoring Dashboards:
- Real-time pipeline status
- Historical performance trends
- Data quality scorecards
- Resource utilization metrics
Expected Outcome: Comprehensive monitoring system providing visibility into pipeline health and performance
Example
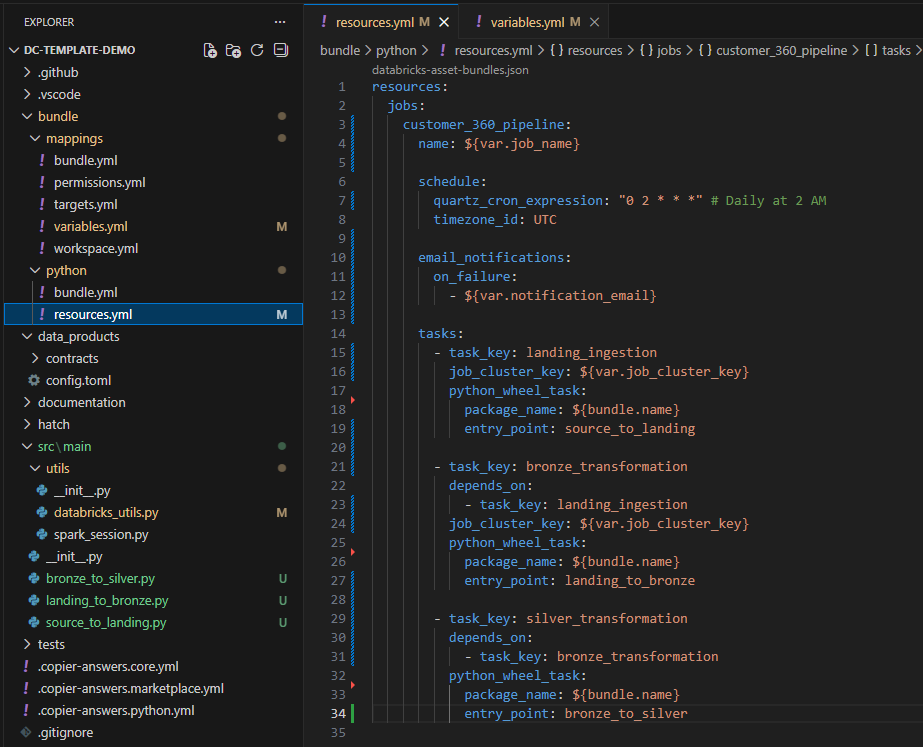
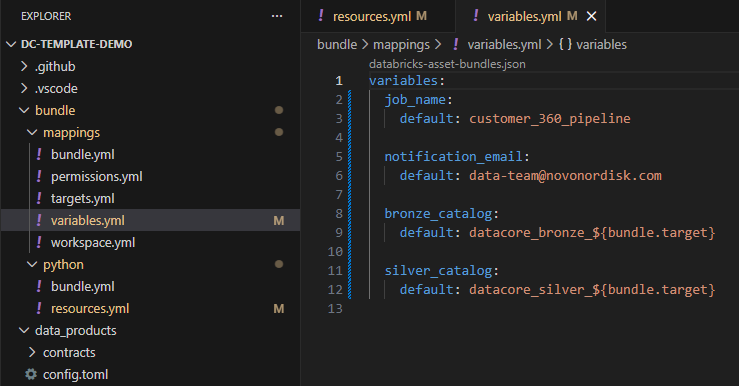
Refer Additional Resources for how to setup observability.
Step 4: Implement Data Quality Controls#
Objective: Ensure data reliability through automated quality checks and validation.
-
Define Quality Rules: - Completeness checks - Accuracy validations - Consistency rules - Uniqueness constraints
-
Implement Quality Checkpoints: - Source data validation - Transformation validation - Output data validation
-
Create Quality Metrics Dashboard: - Quality score trends - Rule violation details - Data profiling results
-
Set up Quality-based Alerts: - Critical quality failures - Quality score degradation - Anomaly detection
Expected Outcome: Automated data quality monitoring with defined thresholds and alerting
Example
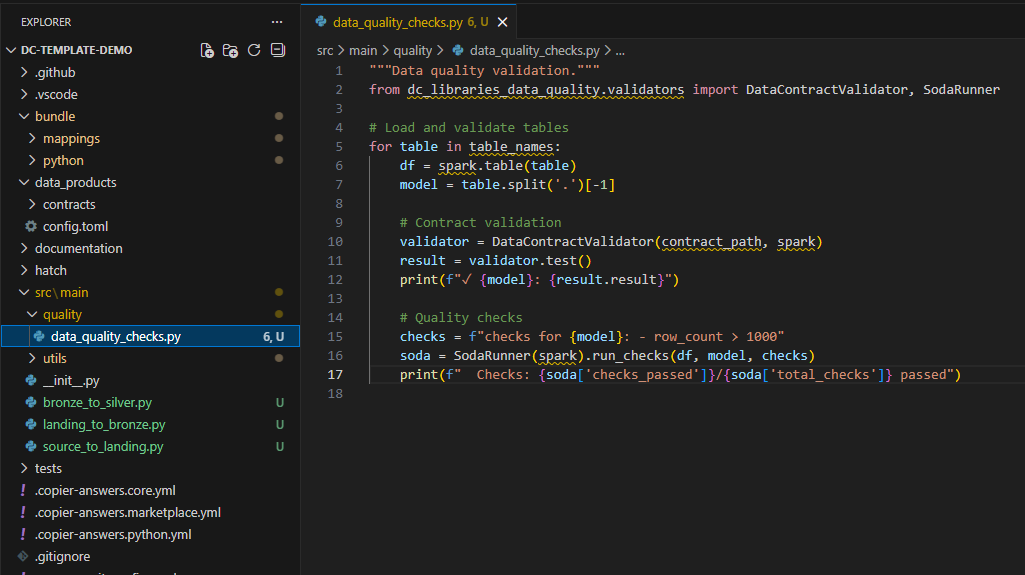
Refer below Additional Resources to see reference implementation
Step 5: Create Data Lineage and Documentation#
Objective: Provide transparency and traceability for your data product.
-
Implement Automated Lineage Tracking:
-
Generate Technical Documentation: - Data schema documentation - Transformation logic descriptions - Pipeline architecture diagrams - Configuration and deployment guides
-
Create Business Documentation: - Business glossary updates - KPI calculation explanations - Usage guidelines - SLA definitions
-
Maintain Version Control:
Expected Outcome: Comprehensive documentation and automated lineage tracking
Example
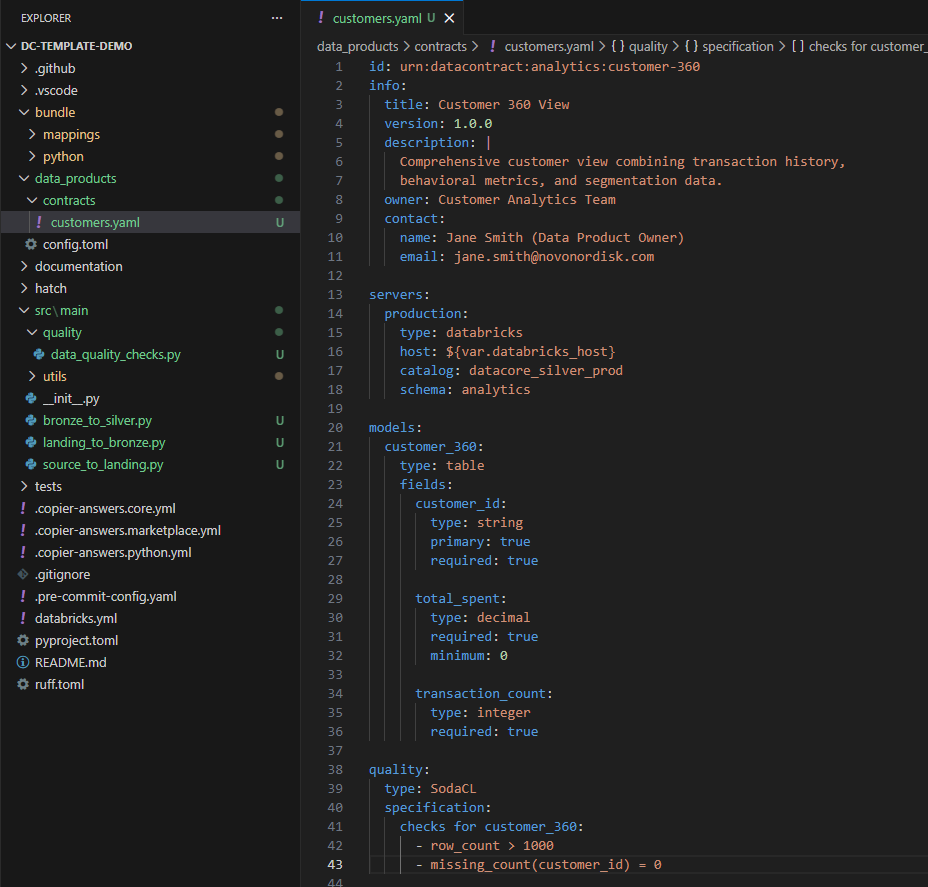
Refer below Additional Resources to understand lineage tracking on a tool like Purview.
Step 6: Configure Output Ports and Data Sharing#
Objective: Establish secure, efficient interfaces for downstream data consumption.
- Define Output Interfaces:
- Direct table access (for analytical workloads)
- API endpoints (for application integration)
- File exports (for external systems)
- Data shares (Snowflake secure shares, Databricks Delta Sharing)
- Configure Access Controls:
- Role-based access permissions
- Data classification labels
- Usage monitoring and auditing
- Create Consumer Documentation:
- API specifications
- Schema definitions
- Usage examples
- Support contact information
Expected Outcome: Well-defined, secure output ports ready for consumer access
Refer below to see reference implementation
- [Source Aligned data products]link to come
- [Customer Aligned data products]link to come
- [Aggregate data products]link to come
Success Metrics & Checkpoints#
- Source Connectivity: All data sources accessible with documented connection patterns
- Pipeline Functionality: End-to-end data flow processing correctly from source to output
- Quality Controls: Data quality rules implemented with automated monitoring and alerting
- Observability: Comprehensive monitoring dashboards and alerting systems operational
- Documentation: Technical and business documentation complete and accessible
- Output Ports: Consumer interfaces configured with proper access controls
- CI/CD Integration: Automated deployment pipeline operational with quality gates
- Performance Validation: Pipeline meets defined SLA requirements under expected load
Common Challenges & Solutions#
- Challenge: Source system connectivity issues or changing APIs
- Solution: Implement robust retry logic and connection pooling; establish SLAs with source system owners
-
Prevention: Build comprehensive error handling and establish monitoring for source system availability
-
Challenge: Performance bottlenecks in data processing
- Solution: Implement incremental processing, optimize joins, and partition data appropriately
-
Prevention: Conduct performance testing during development and establish baseline metrics
-
Challenge: Data quality issues not detected until downstream consumption
- Solution: Implement comprehensive quality checks at each pipeline stage with immediate alerting
-
Prevention: Define quality rules during requirements phase and implement validation early
-
Challenge: Complex transformation logic difficult to maintain and troubleshoot
- Solution: Modularize transformations, add comprehensive logging, and create unit tests
- Prevention: Follow coding best practices and conduct regular code reviews
Next Steps#
During the final stages of implementation, prepare for production launch:
- Finalize Training Materials: Create user guides, training presentations, and FAQ documents
- Schedule User Training: Organize sessions for different user groups (analysts, business users, technical consumers)
- Plan Launch Communications: Coordinate announcements and stakeholder notifications
- Prepare Support Structure: Establish escalation procedures and support contact information
- Validate Production Readiness: Conduct final end-to-end testing in production environment
The next chapter will guide you through Data Product Verification to ensure your implementation meets all requirements before launch.
Additional Resources#
-
Templates
- If you want to accelerate your development, you can use these templates to quickly and easily scaffold the project structures, CI/CD pipelines, Databricks Asset Bundle configurations
- dc-template-core - Core template with project scaffolding and best practices for CICD and Databricks workflows.
- dc-template-python-project - Python project structure with testing, packaging, and CI/CD. Modify the data processing modules for your use case.
- If you want to accelerate your development, you can use these templates to quickly and easily scaffold the project structures, CI/CD pipelines, Databricks Asset Bundle configurations
-
Reference Implementations:
- Source Aligned Data products
- [Customer Aligned data products]link to come
- [Full data product creation flow]link to come
-
Observability & Monitoring:
- How to setup observability: Coming Soon
- How to setup lineage tracking using Purview: Coming Soon