Commonly Used Data validation and error handling Techniques#
*** Work In progress.
The pages covers the key techniques that should be incorporated into every ingestion pipeline.
Data Quality Techniques#
Key Elements of Data Quality for Pipelines#
Data quality is fundamental to the success of any data pipeline—especially in the context of Databricks' Medallion Architecture (Bronze, Silver, and Gold layers), where data flows through various stages of refinement.
Key elements of data quality include:
- accuracy (ensuring the values in the data are correct and reliable),
- completeness (validating that no critical data points are missing),
- consistency (maintaining uniform formatting and semantics across datasets),
- validity (ensuring data complies with defined business rules or constraints),
- timeliness (ensuring that data arrives and is processed within acceptable timeframes), and
- lineage (tracking data origins and transformations for traceability).
At each layer of the Medallion Architecture, specific quality checks should be implemented: basic validations in the Bronze layer (e.g., schema conformity), enhanced quality assurance in the Silver layer (e.g., deduplication and filtering), and business rule validations in the Gold layer.
#
Why It's Important to Introduce Data Quality in Pipelines
Introducing data quality into data pipelines is critical because poor-quality data can lead to inaccurate insights, broken downstream workflows, and loss of trust among stakeholders. Inconsistent or invalid data can cascade through the pipeline, compounding errors as it moves from raw ingestion in the Bronze layer to the refined datasets in the Silver and Gold layers. Without robust data quality measures, businesses are at risk of making erroneous decisions that may impact operations, strategy, and customer satisfaction. Moreover, identifying and resolving data issues earlier in the pipeline is far cheaper and less disruptive than addressing them downstream. By embedding data quality checks (e.g., validations, monitoring, and alerting) into every stage of the pipeline, organizations can ensure data reliability, reduce technical debt, and foster trust in analytics and decision-making processes. For data engineers, prioritizing data quality is essential to building resilient and scalable data systems that empower the business with accurate and actionable insights.
Click here to view the Novo Nordisk data quality reference materials.
Soft Deletes#
Industry Definition
In the context of the Databricks Medallion Architecture, soft deletes are an industry practice wherein records are logically marked as deleted without physically removing them from the dataset. Instead of fully deleting a record, a flag or status column (e.g., is_deleted, deleted_flag, or valid_to) is used to indicate whether a particular record should be treated as deleted or inactive. This allows engineers, analysts, and downstream systems to decide whether to exclude or include the "deleted" records based on the context of their queries or use cases.
For instance, in a dataset, active records might have an is_deleted field with a value of false, whereas logically deleted records would have it set to true. Alternatively, temporal data techniques might involve maintaining a valid_from and valid_to timestamp to identify the active period of a record while preserving historical changes.
coming soon - POC Implementation
Data Validation Techniques#
Industry Definition
In the context of Databricks and broader data engineering practices, data validation techniques refer to the processes and methods used to ensure the accuracy, quality, integrity, and compliance of data as it moves through ingestion, transformation, and refinement within a data pipeline. The goal of data validation on Databricks is to guarantee that data processed through the Medallion Architecture (Bronze, Silver, and Gold layers) adheres to the required business and technical rules, remains reliable for analytics, and avoids propagating invalid or corrupted data downstream.
Data validation techniques enforce safeguards at every stage of the pipeline—from raw ingestion to enriched datasets—using a combination of programmatic checks, rules, and automated workflows. These techniques take advantage of Databricks’ key features, such as Apache Spark, Delta Lake, and notebook-based workflows.
- Schema Validation
- Null Checks and Completeness Validation
- Data Integrity Validation
- Domain/Custom Business Rule Validation
- Duplicate Detection and De-duplication
- Timeliness Validation
- Statistical and Anomaly Detection
- Data Profiling and Monitoring
The diagram below shows for both the bronze and silver layer transformations how the data validation processes are implemented. The sections that follow explain the approach and then show how they are physically implemented.
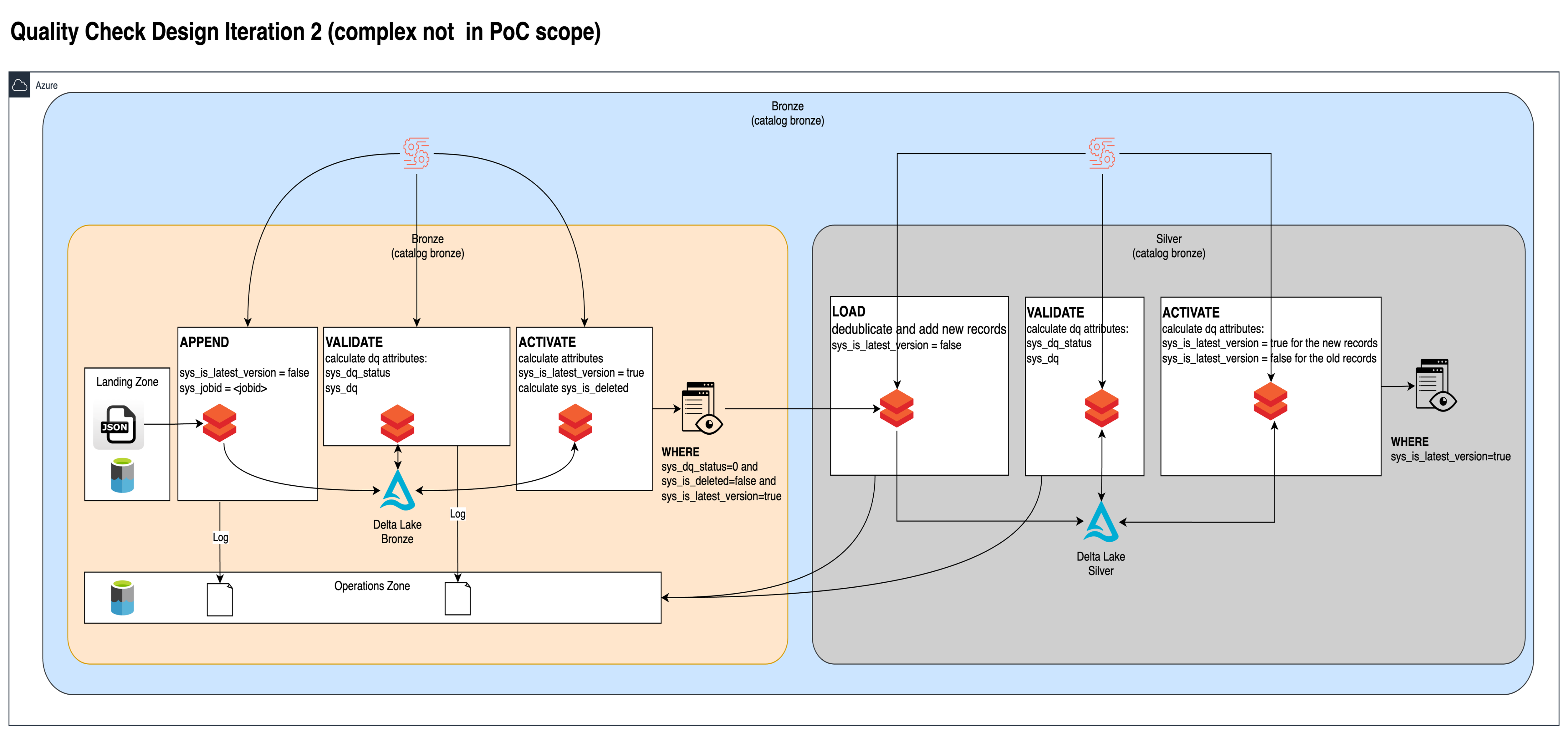
coming soon - POC Implementation
Append#
coming soon...
Validate#
coming soon...
Activate#
coming soon...
Error Handling Techniques#
Industry Definition
In the context of Databricks and its Medallion Architecture (Bronze, Silver, and Gold layers), error handling techniques refer to the strategies and tools used to detect, manage, and resolve errors that occur during data ingestion, transformation, and processing. Error handling ensures data reliability, maintains pipeline stability, and prevents data quality issues from propagating downstream. Because Databricks is built on Apache Spark and Delta Lake, error handling needs to account for distributed processing, schema enforcement, and large-scale data volumes.
Below are commonly used error handling techniques in Databricks:
- Schema Enforcement and Validation Errors
- Data Quality Rules with Error Segregation
- Try-Catch Blocks for Code-Level Errors
- Quarantine Invalid Records
- Delta Lake Transactions and Upserts
- Checkpointing and Watermarking for Fault Tolerance
- Monitoring and Alerts for Failures
- Idempotent Pipeline Design : Design pipelines to be idempotent, so if errors occur and the pipeline is rerun, it doesn’t cause duplicate processing or inconsistent data states. Delta Lake simplifies this with merge operations and updates.
- Custom Exception Logs
- Retry Logic for Recoverable Errors
- Error Classification and Prioritization
Click here to view some best practices on error handling
coming soon - POC Implementation
Data Historisation Techniques#
Industry Definition
Data historization refers to the process of efficiently capturing, storing, and managing changes to data over time to build a historical record of its state across various points in time. In the data engineering and analytics industry, historization ensures that any changes to records (e.g., inserts, updates, and deletions) are preserved, enabling the reconstruction of past conditions, performing trend analysis, or conducting audits. This is particularly important for compliance with regulatory requirements, troubleshooting, building time-series insights, and supporting slowly changing dimensions (SCDs) in data warehouses/data lakes.
In the context of modern platforms like Databricks, data historization is often implemented using technologies such as Delta Lake, which supports time travel and transactional versioning, enabling seamless tracking of data changes.
Types of Data Historization: - Full History Storage (Append-Only): - Time Travel or Version Control: - Change Data Capture (CDC): - Slowly Changing Dimensions (SCD):
coming soon - POC Implementation
Deduplication Techniques#
Industry Definition
Deduplication refers to the process of identifying and removing duplicate records or data points from a dataset to ensure data consistency, accuracy, and reliability. In the context of Databricks, deduplication techniques are crucial for maintaining high-quality datasets across the Medallion Architecture (Bronze, Silver, and Gold layers). By removing duplicates, data engineers can prevent inflated metrics, erroneous analytical insights, and unnecessary storage costs.
Deduplication can be applied at various stages of the data pipeline, depending on the layer and requirements:
- **Bronze Layer**: Minimal scrubbing to preserve raw ingested data while tracking duplicates for auditability.
- **Silver Layer**: Comprehensive deduplication to create clean datasets for downstream processing.
- **Gold Layer**: Advanced deduplication aligned with business rules to ensure dataset accuracy for reporting and analytics.
coming soon - POC Implementation